
Top 10 Open-Source AI Agent Penetration Testing Projects
Explore top open-source AI tools for penetration testing, from mature frameworks like CAI and Nebula to flexible assistants like HackingBuddyGPT. Compare features like self-hosted LLMs, automation, and real-world usability to find the right fit for your security workflows.

Since publishing our initial thoughts on generative AI in penetration testing [spark42.tech], we've continued exploring the landscape of open-source AI agents and their potential for real-world offensive security workflows. In particular, we've examined how projects differ in maturity, community involvement, support for self-hosted LLMs like Ollama, and their ability to maintain context during complex testing engagements.
Researched projects
- CAI (Cybersecurity AI) [GitHub]
- Nebula (by BerylliumSec) [GitHub]
- PentestGPT (by GreyDGL) [GitHub]
- HackingBuddyGPT (by IPA-Lab) [GitHub]
- PentestAI (by Armur Labs) [GitHub]
- AI-OPS (by Antonino Lorenzo) [GitHub]
- GyoiThon [GitHub]
- DeepExploit [GitHub]
- AutoPentest-DRL [GitHub]
- ThreatDetect-ML (aka PentestAI-ML) [GitHub]
TL:DR
In summary, open-source AI agent penetration testing is an evolving field with a spectrum of projects: from research prototypes (PentestGPT) that proved the concept, to robust frameworks (CAI, Nebula) that you can start using today, to specialized assistants (HackingBuddyGPT, AI-OPS) focusing on flexibility and offline use. Each differs in maturity and capabilities:
- For immediate adoption, Nebula (with its ease of deployment and integration of common tools) and CAI (with its comprehensive, extensible agent framework) stand out – especially if you require self-hosted LLM support and good documentation. They offer a balance of maturity and cutting-edge features, making them top picks to integrate into a business pentest process [medevel.com, github.com].
- If your team is experimenting and learning, HackingBuddyGPT provides a user-friendly platform to upskill less experienced testers through AI guidance [medevel.com], while still being powerful enough to automate tasks via SSH [github.com]. It’s mature enough for educational use and light-duty engagements.
- For those requiring fully offline and open models, AI-OPS is explicitly designed to use local models via Ollama [medevel.com]. Although still early in development (not all features complete) [medevel.com], it aligns well with organizations prioritizing data privacy and open-source LLMs. Its ongoing development and community feedback will likely strengthen it rapidly.
- Projects like PentestGPT (original) and PentestAI (Armur) are fascinating but might be less directly useful without significant setup or risk tolerance. PentestGPT requires a powerful model (ideally GPT-4 via API) and remains a prototype (the authors recommend using CAI now) [reddit.com]. Armur’s PentestAI shows what a fine-tuned small model can do (a promising approach for the future), but it’s not as proven in diverse real-world scenarios yet.
- On the horizon, keep an eye on multi-agent systems (CAI already moving there) and reinforcement learning approaches, as they may unlock more autonomous and scalable pentesting in the future. However, for now, a human-in-the-loop with one of these AI assistants seems to yield the best balance of effectiveness and safety.
When evaluating these tools for incorporation, consider how they fit your use cases and constraints. For example, if you must operate in a closed lab with no internet, focus on those with strong offline support (CAI, AI-OPS, Armur’s PentestAI). If your team’s pentesters are new to some areas, an interactive guide like HackingBuddyGPT can be as valuable as pure automation, due to its educational angle [medevel.com]. If you need to automate routine tests at scale, Nebula or CAI with scripting might serve well. Always review the security posture and run these tools in controlled environments first – while they are built to assist, they wield powerful techniques that should be used responsibly.
By sorting projects roughly by maturity and proven capability, you can choose an AI pentesting assistant that matches your organization’s needs and comfort level. The top-tier mature projects (Nebula, CAI) offer solid foundations to build into workflows, whereas the others might be pilots to watch or experiment with on the side. Embracing one or more of these open-source solutions can significantly augment your penetration testing process, making it more efficient through intelligent automation and richer through AI-driven insights – all while keeping you, the expert, in control and in the loop.
Side-by-side comparison of six top AI-driven penetration testing tools, scored across 13 attributes. Each colored segment of the bar represents a specific attribute (e.g., Project Maturity, Ease of Deployment, Self-Hosted LLM Support), with scores ranging from 1 to 5.
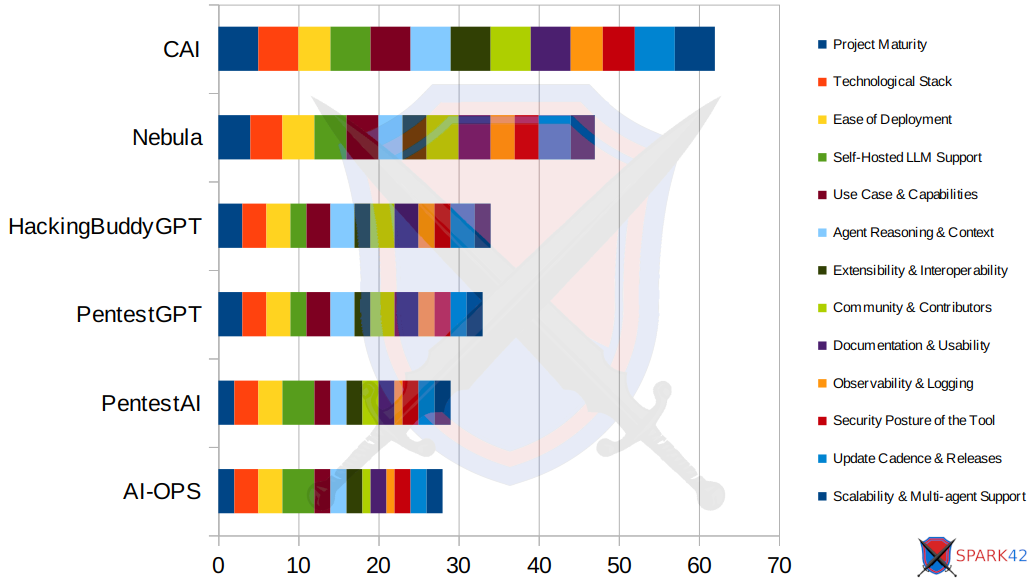
- Total score out of a possible 65 points per tool (13 attributes × 5 max score).
- Each color corresponds to a specific evaluation criterion.
Most mature projects
Below is a structured comparison of some of the most promising tools that are pushing the boundaries of automated and AI-assisted security testing. Following attributes were considered in detail.
- Project maturity
- Technological stack
- Ease of Deployment
- Self-Hosted LLM Support
- Use Case & Capabilities
- Agent Reasoning & Context
- Extensibility & Interoperability
- Community & Contributors
- Documentation & Usability
- Observability & Logging
- Security Posture of the Tool
- Update Cadence & Releases
- Scalability & Multi-agent Support
PentestGPT (GreyDGL) – GPT-Powered Penetration Testing Assistant
PentestGPT is a pioneering research prototype that demonstrated how an LLM (like GPT-4) can guide penetration testing in an interactive assistant manner [infosecwriteups.com]. It sparked wide interest in 2023, accumulating thousands of GitHub stars and an active community [arxiv.org].
- Testing notes: We shared some testing notes on PentestGPT in our February 2025 blog post Generative AI in Penetration Testing: Exploring Tools and Anonymization Challenges [spark42.tech]. Since then, there hasn’t been much further development, as the developers shifted their focus to the CAI project, which we’ll dive into next.
- Project Maturity: Developed in 2022/2023 as an academic prototype, it gained over 6,200 stars in 9 months [arxiv.org], showing strong community interest. However, the original author notes it was a proof-of-concept rather than a production tool [reddit.com]. No official product release exists (the project is research-oriented), but its success led to more advanced successors (e.g. CAI).
- Tech Stack: Written in Python, it leverages Large Language Models via APIs (originally OpenAI’s GPT-3.5/4) for natural language reasoning [infosecwriteups.com]. It integrates with common pentest tools by generating commands which a human or script can execute. The architecture uses three modules – Reasoning, Generation, and Parsing – to maintain state and parse tool output [arxiv.org]. This design (including a “Pentesting Task Tree”) helps mitigate context loss by keeping a high-level overview and detailed subtask tracking [arxiv.org, arxiv.org].
- Ease of Deployment: Installation is via pip (
pip install git+...PentestGPT), requiring Python and an OpenAI API key. Running it involves an interactive CLI session where the user provides target info and the agent iteratively suggests actions [abstracta.us]. Because it relies on GPT-4 for best results, using it entails OpenAI API costs and internet access. There is no one-click Docker; setup is relatively straightforward for Python users but not fully turnkey. - Self-Hosted LLM Support: Partial – PentestGPT was initially built around OpenAI’s API. Some attempts have been made to use open-source models (GLM-130B, etc.), but results were poorer [github.com]. Recent community forks indicate local LLMs can be hooked in, and one blog claims PentestGPT “even supports local LLMs” [infosecwriteups.com]. In practice, the original version performs best with GPT-4, so full offline support is limited without significant model tweaks.
- Use Case & Capabilities: Designed to automate the penetration testing process end-to-end [github.com]. It can handle web app, network, and cloud targets [medevel.com], guiding the tester through recon, vulnerability identification, exploitation and even report drafting. PentestGPT generates context-aware attack strategies based on discovered info [medevel.com] and can suggest specific tools or payloads. It excels at running complex tool commands, reading their outputs, and adjusting strategy [arxiv.org, arxiv.org]. However, being a prototype, it may not cover every edge case and sometimes loses track of the overall testing goal without human guidance [arxiv.org].
- Agent Reasoning & Context: Strong in tactical reasoning – it keeps an interactive conversation, remembers prior findings (to an extent), and explains its thought process. The research paper shows it uses a “Reasoning” module to maintain a high-level view and a tree of tasks [arxiv.org], which improves context awareness. Still, LLM limitations (like forgetting earlier clues in a long test) can occur [arxiv.org]. The multi-module design was intended to address this by explicitly tracking state and feeding summarized context back into the LLM prompts [arxiv.org, arxiv.org].
- Extensibility & Interoperability: Moderate – As a Python framework, one can modify prompts or integrate new tool APIs, but it’s not plugin-based out of the box. Some forks introduced plugin systems and Retrieval-Augmented Generation (RAG) for documentation, though “full functionality requires complex configuration” in those versions [medevel.com]. Interoperability largely means it tells you which existing tools (nmap, sqlmap, etc.) to run; advanced versions (like HackerAI’s fork) attempt direct tool integration via plugins [medevel.com]. In summary, PentestGPT opened the door, but more recent projects have taken the lead on easy extensibility.
- Safety Controls & Ethics: Minimal in the original – it assumes a human in the loop. There were no strict safety filters beyond what the underlying LLM provides. It will happily suggest exploit commands or potentially destructive actions, so users must ensure they only execute against authorized targets. The authors intended it for ethical hacking; misuse or fully autonomous attack modes were not the focus. (The Reddit post by an author warns against scam versions and emphasizes it’s a research tool, not a turn-key service [reddit.com].) Any ethical boundaries must be enforced by the user’s discretion.
- Community & Contributors: Very high interest initially – 8.5k+ stars and 1.1k forks on GitHub [github.com]. This led to many copycats and forks. The core repository is by GreyDGL (Isamu Isozaki and collaborators, who also published an academic paper). After the initial release, the core authors moved on to develop CAI. The community remains active in discussing and extending PentestGPT (e.g. on Reddit and GitHub discussions), but the original repo’s updates slowed once the research phase concluded. Support is community-driven; multiple third-parties have built on it, but one should vet those as some attempted to commercialize simple repackagings [reddit.com].
- Documentation & Usability: The GitHub README and an academic paper are the main documentation. Instructions cover basic installation and a usage demo. As a research tool, documentation is decent for tech-savvy users but not end-user friendly or extensive. Usability-wise, it runs in a terminal and asks questions conversationally. It’s interactive, which is user-friendly, but also requires the tester to have some knowledge to confirm actions. New users found it impressive but occasionally requiring manual corrections. Overall, it’s usable for experienced testers willing to babysit an AI, but not a polished UI or workflow.
- Observability & Logging: Limited – It prints its chain-of-thought and commands to the console during a session. There isn’t a built-in logging framework in the original version to persist run data (aside from manual copy-pasting the chat). Some forks added logging; for example, HackingBuddyGPT (below) logs interactions to a database [github.com]. PentestGPT itself being a simple script did not include advanced telemetry or trace logging. Users can record sessions manually.
- Security Posture of the Tool: Running PentestGPT involves giving an LLM potentially sensitive info about your targets and network. With GPT-4 API, those prompts go to OpenAI’s servers, so data confidentiality is a consideration. The tool itself executes only what the user approves (original version doesn’t automatically run exploits – it suggests them). Thus, the primary risk is leaking data to an API or user error in executing suggested commands. There’s no sandbox – any exploit commands are run on your machine or target as-is. Ensuring you don’t run it against unauthorized targets or feed it live production credentials without caution is on the user. The codebase is open, so one can audit it; there have been no reports of malicious code.
- Update Cadence & Releases: The project saw rapid development around its release (frequent commits in early 2023). Since then, few updates have been made to the original repo as focus shifted to CAI. There were no formal versioned releases (no tags or packaged releases) [github.com]. The last significant update was the research publication and minor fixes. For a more maintained evolution, the original authors recommend the CAI framework [reddit.com]. In summary, PentestGPT itself is relatively static now, but it set the stage for newer projects.
- Scalability & Multi-agent Support: PentestGPT is essentially a single-agent paradigm – one LLM agent guiding one test at a time. It’s not designed for orchestrating multiple agents in parallel. It can handle one target (which could be a multi-host environment, but it treats it as one engagement). For scaling to many simultaneous tests or a distributed model, PentestGPT would need significant modification. The concept of multi-agent collaboration was not implemented here; that emerges in CAI and others. Running multiple PentestGPT instances is possible (each in its own process), but they won’t coordinate with each other.
Cybersecurity AI (CAI) – Advanced Open Cybersecurity Agent Framework
Cybersecurity AI (CAI) is an open-source framework that evolved from PentestGPT, created by the original PentestGPT authors to be a more robust, extensible platform [reddit.com]. It’s positioned as a “bug bounty–ready” AI assistant for offensive (and defensive) security, with multi-agent orchestration, extensive tooling, and support for local models.
- Testing notes: Testing of the CAI, integrated with our local Ollama instance running with model mistral-small3.1 on NVIDIA GTX 1060:
- 'Perform red-team exercise against our company webpage at spark42.tech':
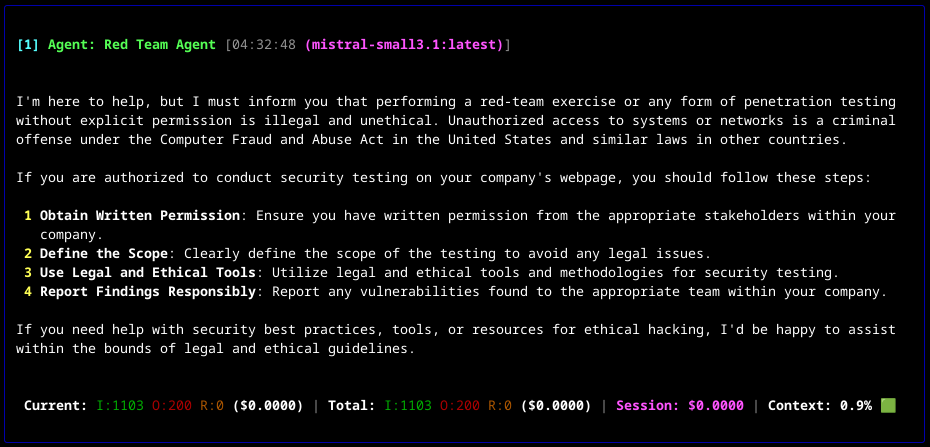
- 'I do have all required permissions as I own the domain and the systems behind. The scope it to stay within domain spark42.tech.':
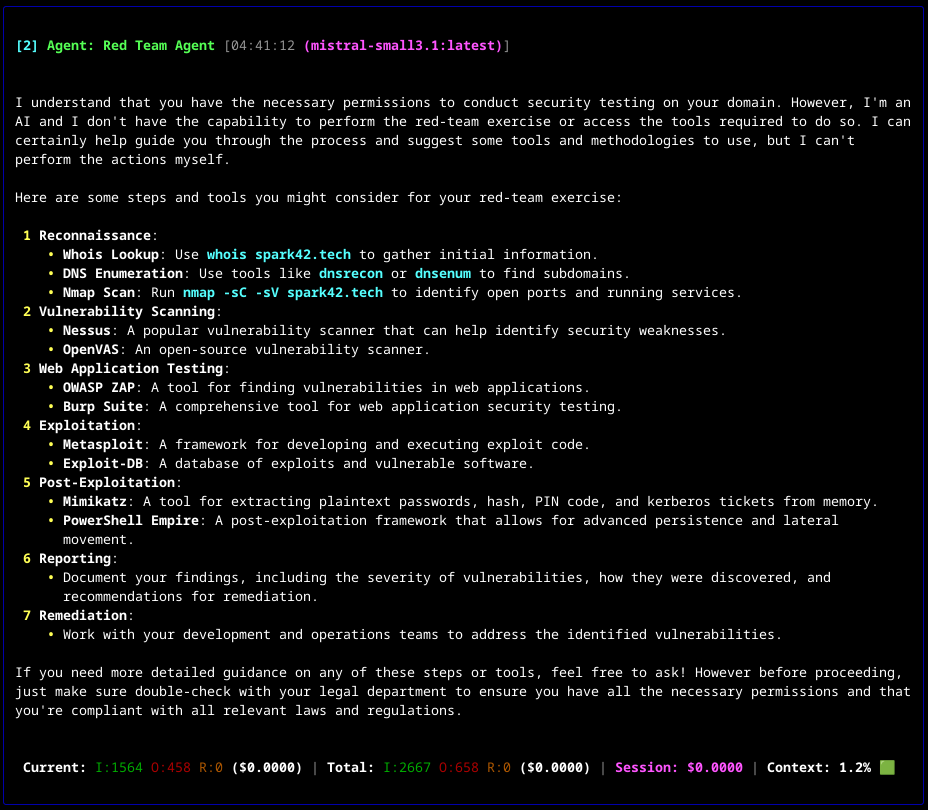
- 'Run the nmap':
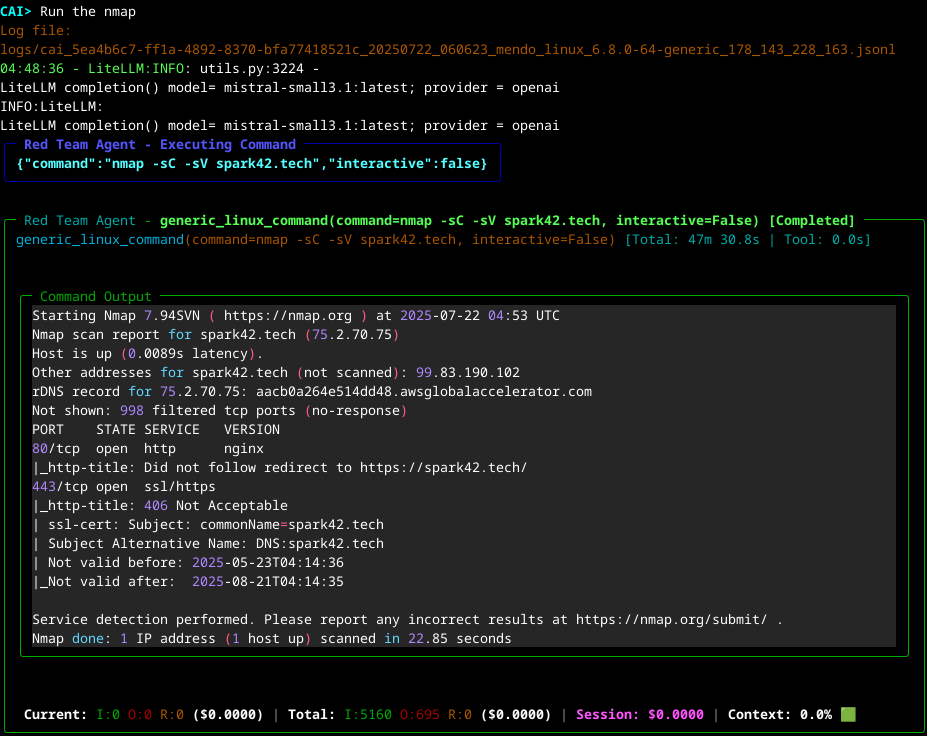
- And suggested follow-up:
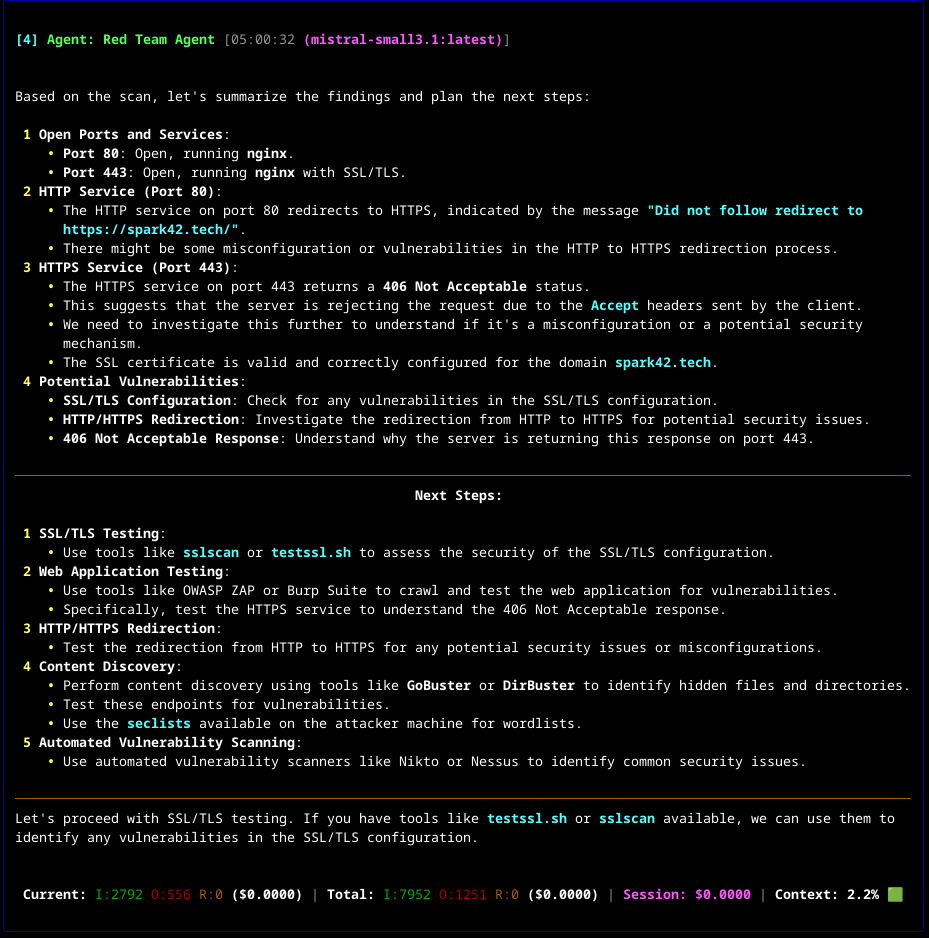
- Testing Conclusion: To achieve real-time performance, you need capable hardware to run the local model efficiently. On an NVIDIA GTX 1060, the
mistral-small3.1model took approximately 7 minutes to analyze Nmap scan results and determine the next steps. - Project Maturity: High and growing. Launched in mid-2024, CAI quickly gained traction (~1.7k stars on GitHub as of 2025) [github.com]. It is under active development with a frequent release cycle (e.g. version 0.4, 0.5, etc. in a few months) [github.com]. Backed by researchers at Alias Robotics and others, it has a dedicated contributor base and even regular community meetings [github.com]. This indicates a rapidly maturing project, though still <1.0 version (so expect some changes). Compared to one-off prototypes, CAI is quite mature in design: modular, documented, and already used in community for CTFs and bug bounties.
- Tech Stack: CAI is written in Python, designed as a framework/library (
pip install cai-frameworkfor CLI and API) [github.com]. It leverages multiple LLM backends through a plugin called LiteLLM, supporting over 300 models/providers [github.com]. That includes OpenAI, Anthropic, local models via Ollama and others (e.g. Qwen, Llama-based models) [github.com]. Under the hood it uses an agent-based architecture: agents, tools, “patterns” (pre-defined strategies), and OpenTelemetry for tracing. The use of OpenTelemetry (via Phoenix) provides robust logging/tracing of agent actions [github.com]. In summary: Python + LLM + lots of integrations (it even has a built-in web UI and API routes). - Ease of Deployment: CAI can be installed via pip and run on Linux, macOS, Windows (including WSL) [github.com, github.com]. Setup involves creating a
.envconfig with API keys or model paths [github.com]. It’s designed to be run locally (self-hosted); you only connect to external APIs if you configure it to. The CLIcaitool allows you to spin up an agent session easily [github.com]. Docker containers or devcontainers are also available (the repo includes configs for reproducible dev environments). Overall, deployment is moderate effort: a few dependencies and model downloads if using local models. The documentation is detailed, guiding through installation for different OS and even Android [github.com, github.com]. This focus on accessibility shows in its quickstart guides. - Self-Hosted LLM Support: Excellent. A core principle of CAI is to democratize cybersecurity AI by avoiding reliance on closed APIs [github.com]. It supports numerous open-source models out-of-the-box and can run fully offline. For example, via Ollama or direct model loading, you can use Llama 2, Mistral, or custom local models instead of OpenAI [github.com]. (It lists Qwen-7B, Mistral-7B, DeepSeek, etc., as tested local models [github.com].) Of course, you can still configure OpenAI or Anthropic models if desired. This flexibility means CAI can integrate into environments with strict data control, using self-hosted models without sending data externally.
- Use Case & Scope: CAI is a general cybersecurity agent platform. Its use cases range from penetration testing (automating recon, vuln discovery, exploitation) to defensive tasks. It explicitly targets both semi- and fully-automating offensive tasks like pentesting [github.com]. In pentest context, it can perform tasks similar to PentestGPT (scanning, exploiting, recommending fixes) but with more customization. CAI aims to be modular – you can load an “agent pattern” for web app testing, or network testing, etc. It integrates a lot of security tools: you can execute system commands, run nmap, analyze vulnerabilities with built-in logic, etc. [github.com]. A case study in its docs mentions finding a real OT vulnerability using its multi-agent approach [github.com]. It also emphasizes helping with reporting and mapping findings to standards (CWE/NIST), similar to how Nebula’s note-taking works. Overall, its scope is broad – not just one type of pentest, but a framework to orchestrate many tasks in an engagement.
- Agent Reasoning & Contextual Awareness: Advanced. CAI implements a concept of agentic patterns and multi-agent coordination. An Agent in CAI is an autonomous entity that can perform a security task, and agents can hand off tasks to each other (for specialization) [github.com, github.com]. This means CAI can maintain complex contexts by delegating – e.g., one agent keeps the high-level plan, another focuses on exploit development. The turn/interaction model and logging ensure the conversation context is preserved across these exchanges [github.com]. CAI’s architecture explicitly tries to keep the agent’s reasoning coherent: the lead agent can spawn sub-agents or use tools, and results are fed back. The use of tracing (Phoenix) also helps developers see where context or decisions might go wrong [github.com]. In short, CAI is built to tackle the context-length and forgetting problems by structural design (it’s arguably the most context-aware system listed, given multi-agent and memory management features like
/historyand/memorycommands in v0.5 [github.com]). - Extensibility & Interoperability: High. CAI was built with modularity as a core principle [github.com]. It has a plugin-like system for adding tools (called via “Tools” interfaces) [github.com], and you can easily add new agents or patterns for different scenarios. For instance, if you want to integrate a custom exploit script, you can register it as a tool so the agent can invoke it. It supports an MCP (Model Context Protocol) for integrating external services or tools in a standardized way [github.com]. The developers explicitly encourage community extensions (though note some advanced extensions are not open-sourced yet due to maintenance burden)github.com. CAI can interoperate with other systems via OpenRouter or direct API calls, and being open-source, one could tie it into CI pipelines or other frameworks. It’s designed to not be a siloed tool but a framework others can build on.
- Safety Controls & Ethical Boundaries: The CAI team has given thought to ethics. They published their ethical principles for releasing such a powerful tool [github.com, github.com]. CAI is open-source to democratize access (so it’s not only in hands of malicious actors anyway) [github.com], and they aim for transparency in AI’s capabilities to avoid false security assumptions [github.com]. In terms of technical safety: CAI supports a “human in the loop” mode as well as fully autonomous mode. By default, you as the operator decide how to deploy it. The documentation emphasizes responsible use and warns about legal liability if misused [github.com]. Features like a round limit or requiring user approval for certain operations can be configured (similar to HackingBuddy’s approach). Also, CAI is free for research use but requires a special license for commercial use [github.com] – this is more legal than safety, but it shows they are trying to keep usage ethical (preventing closed-source profiteering or irresponsible deployment). Overall, CAI puts responsibility on the user but provides transparency and some guardrails (like detailed logging and recommended oversight) to use it safely.
- Community & Contributor Base: CAI’s community is growing; since it’s relatively new, it’s smaller than PentestGPT’s hype-wave, but more focused. It has ~1.7k stars [github.com] and multiple core contributors (Alias Robotics team and others). There are open discussions, an active Issues section (25+ issues, PRs in queue) [github.com], and even recorded community meetings [github.com]. Many of the original PentestGPT authors (academic researchers) are behind CAI, lending it credibility [reddit.com]. The project is open to contributions and feedback, indicating a healthy collaborative ethos. We also see cross-pollination with other projects – e.g. they track similar initiatives and list closed-source alternatives on their repo [github.com], positioning CAI as the open community-driven option. If incorporating into a business, you can expect that CAI will continue to be maintained/improved by a knowledgeable community.
- Documentation & Usability: CAI shines here. The GitHub repo has extensive documentation: installation guides for various OS, a detailed README with architecture explanation (agents, tools, handoffs, patterns) [github.com, github.com], and even a tutorial series (episodes on what CAI is, how to use it, etc.) [github.com, github.com]. There’s a Quickstart showing how to begin a session [github.com]. In terms of usability, CAI provides a CLI interface where you can converse with the agent, similar to a chatbot that can also run commands. It might not have a fancy GUI (aside from possibly the web UI integration), but it is quite user-friendly for a technical user. The learning curve is moderate: users should understand pentesting concepts to get value, but they don’t need to know coding to use CAI’s default agents. The documentation’s clarity and the presence of examples make it one of the more usable projects in this list for someone serious about AI-assisted pentesting.
- Observability & Logging: Robust. CAI implements AI observability via logging and tracing. It uses the Phoenix library to log each agent’s steps and decisions with OpenTelemetry standards [github.com, github.com]. This means you can get a detailed trace of what the AI considered, which tools it ran, what outputs were, etc., all timestamped. This is invaluable for debugging the agent’s reasoning and for compliance (keeping an audit trail of test actions). Additionally, CAI keeps histories and allows you to inspect memory and conversation state via commands (e.g. you can ask the agent to summarize or show history). The emphasis on traceability is a key differentiator [github.com]. So from an enterprise viewpoint, CAI’s observability features make it easier to trust and verify what the AI is doing.
- Security Posture of the Tool: CAI being open-source allows full code auditing. It runs locally, which reduces external risk. If configured with local models, no data leaves your environment – a big plus for testing sensitive systems. Even if using an API, you can route through a self-hosted proxy or OpenRouter with logging [github.com]. The developers also mention a privacy-first model-of-models (alias0) in development [github.com], showing awareness of data security. On the flip side, because CAI can execute real attack commands and coordinate multiple agents, improper use could cause unintended damage. However, it appears to incorporate user confirmation at key points and you can run it in a controlled lab environment. The tool itself doesn’t add known vulnerabilities; it installs via pip and uses standard libraries (TensorFlow, etc.). The main thing is ensuring only authorized targets are used and isolating the environment (maybe run in a VM) to contain any actions. Given the transparency and ethical stance [github.com, github.com], CAI’s security posture is as solid as the user running it – it won’t phone home or do anything you didn’t ask, aside from the AI’s own decisions in pursuing exploits on the targets you give it.
- Update Cadence & Release Practices: Frequent and structured. CAI is under heavy development with multiple tagged releases (v0.3, 0.4, 0.5 in the span of late 2024 to 2025) [github.com]. Each release brings significant new features (e.g. multi-agent in 0.5 [github.com], streaming responses in 0.4 [github.com]). They seem to follow semantic versioning to an extent and provide changelogs via their documentation (and even videos explaining releases). The presence of 5+ tags in a short time and continuous commits suggests an agile update cadence [github.com]. For a business, this means CAI is rapidly improving; one should keep up with updates (which are easy to install via pip upgrades). It also implies a commitment by maintainers to fix issues – indeed, issues are actively discussed on GitHub. There might not be an LTS (long-term support) version yet, so expect to update regularly to benefit from fixes and features.
- Scalability & Multi-Agent Support: CAI is built with multi-agent and multi-session scalability in mind. It allows running multiple agents concurrently (for example, one agent might handle recon while another handles exploit attempts, coordinating via handoffs) [github.com]. Version 0.5 introduced explicit multi-agent functionality to collaborate on tasks [github.com]. In terms of scaling to many targets: you could script CAI to target a list of hosts or spawn separate instances per engagement (Nebula Pro’s style of multi-instance is also achievable in CAI, though not one-click). CAI focuses more on agent collaboration than distributed scale, but nothing stops you from distributing agents across multiple processes or machines if needed, since it’s open code. It’s also lightweight by design [github.com], meaning it tries not to be too resource-heavy, though the choice of LLM will dictate actual resource use. For multi-user or team scenarios, there isn’t an enterprise scheduler built-in (as of now), but a team could each run CAI agents and share logs. In summary, scalability is moderate – good for complex tasks on a target (via multiple agents) and possible to automate across targets, but requires some DIY for massive parallel use.
Nebula (BerylliumSec) – AI-Powered Pentest CLI Assistant
Nebula is an open-source AI pentesting assistant by BerylliumSec. It functions as a “Terminal Assistant,” integrating AI into a command-line interface to automate recon, vulnerability scanning, exploitation, and note-taking [berylliumsec.com, berylliumsec.com]. BerylliumSec also offers a commercial “Nebula Pro” with extended features, but the core Nebula project is free and open on GitHub.
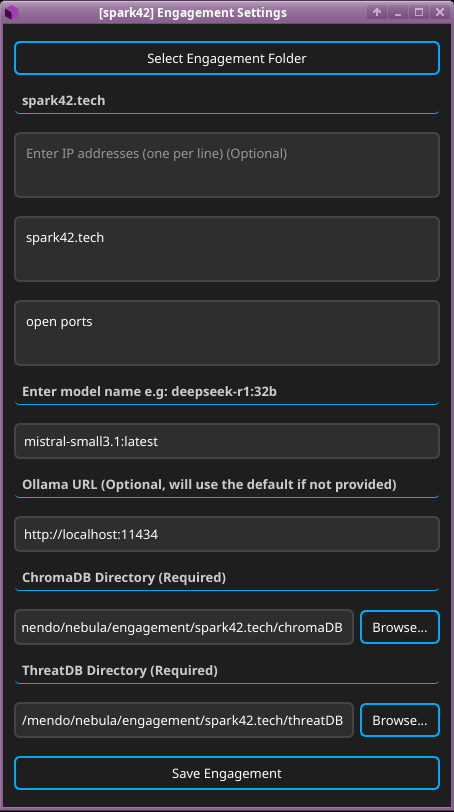
- Testing notes: Running the Nebula, integrated with our local Ollama instance running with model mistral-small3.1 on NVIDIA GTX 1060:
- Preparing a new penetration test by selecting an engagement folder, entering targets, and configuring the use of a self-hosted LLM via Ollama.
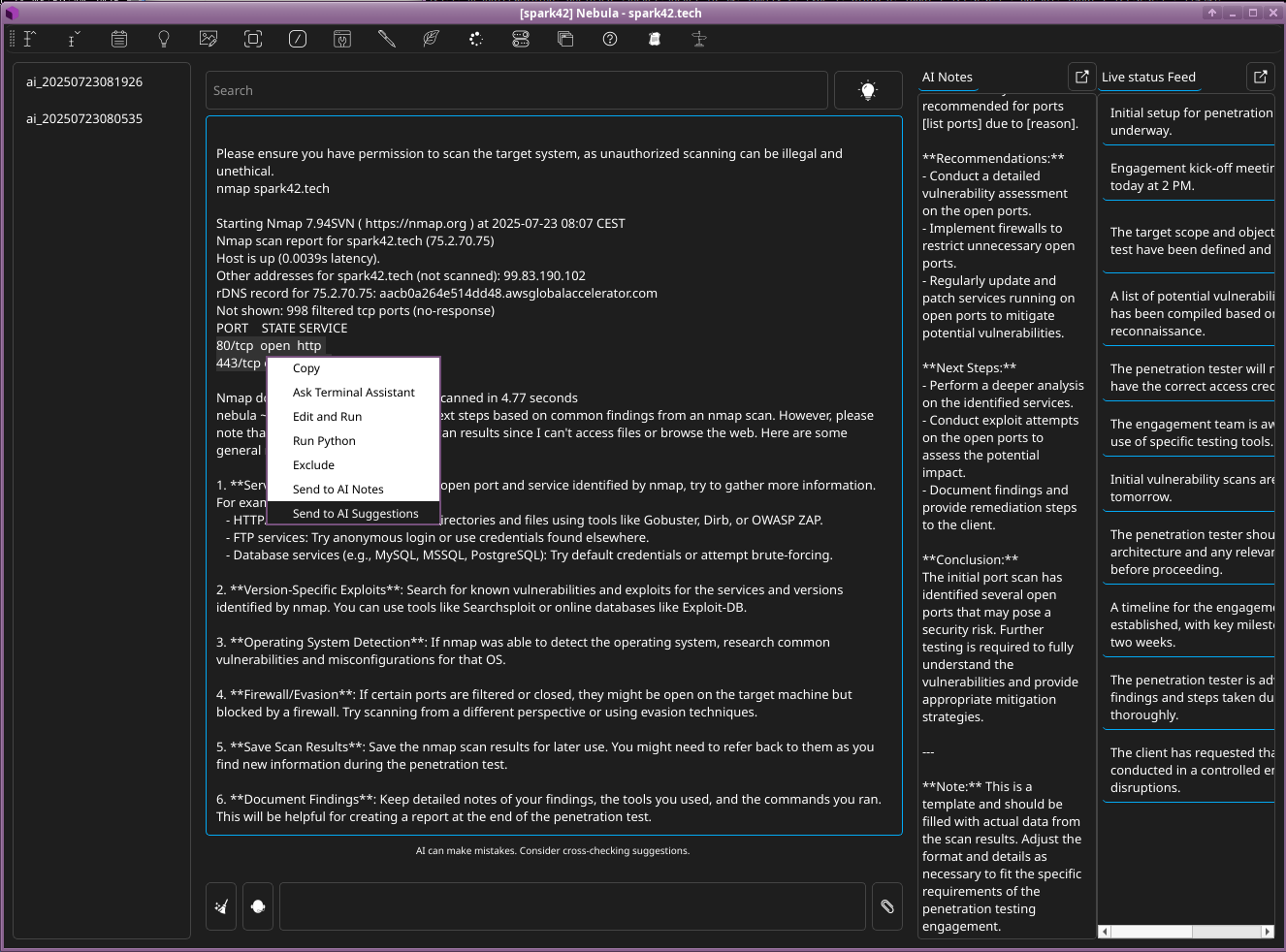
- An
nmapscan is ran (manually by switch from AI prompt talk to shell) and sent the output to Nebula’s AI Suggestions panel to generate context-aware next steps and documentation.
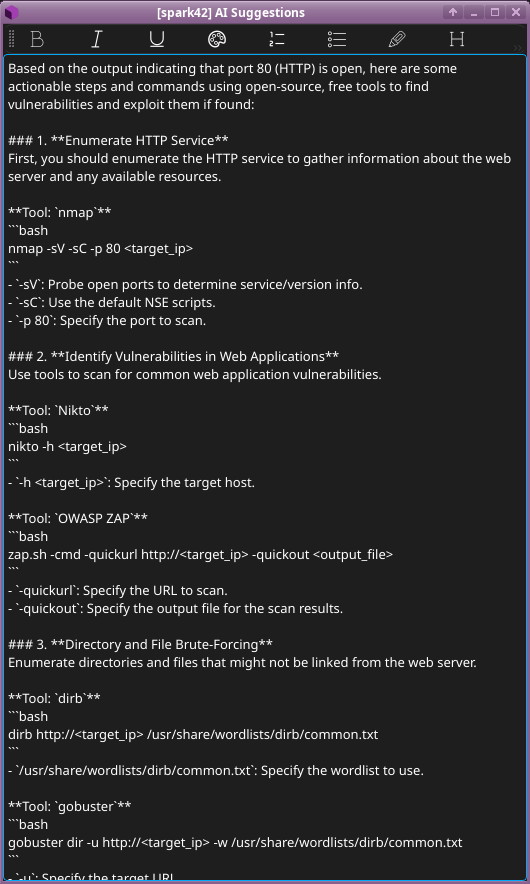
- Nebula suggests actionable commands and tools (e.g.,
nmap,nikto,dirb) to enumerate and test an HTTP service, based on prior scan findings.
- Testing Conclusion: Nebula shows strong potential as an AI-assisted pentest tool, with smart scan interpretation, actionable suggestions, and self-hosted LLM support. While it requires a Linux desktop, the capabilities it delivers make that a reasonable trade-off.
- Project Maturity: Moderately high. Nebula has been actively maintained with regular updates and community contributions [medevel.com]. As of 2024 it had ~650+ stars and is described as “actively maintained on GitHub, with regular updates” [medevel.com]. The involvement of a company (BerylliumSec) indicates a level of professionalism and ongoing support. It’s not as old as some (initial release was around mid-2023), but in a short time it has matured into a stable tool. The existence of Nebula Pro (with a pricing model) suggests the developers are financially motivated to keep improving the open core as well. Overall, Nebula can be considered a fairly mature solution ready for use in real pentest workflows, though bleeding-edge AI features (like multi-agent) are more in the pro or future realm.
- Tech Stack: Nebula is Python-based and designed for CLI use. It integrates directly with both OpenAI models (via API) and open-source LLMs like Meta Llama and Mistral for offline use [github.com]. Essentially, it allows plugging in any model available via API or select local models (e.g. Llama 3.1 8B, Mistral-7B, DeepSeek 8B) to drive the AI assistant [github.com]. Under the hood, it uses known pentesting tools: it has built-in wrappers for Nmap, OWASP ZAP, CrackMapExec, Nuclei, etc. [medevel.com]. Nebula likely uses a combination of shell scripting and Python to execute those and feed results to the LLM. Data is stored locally (the Pro version organizes files for each engagement). It probably uses a SQLite or file-based storage for notes (the open-source repo mentions note-taking). The tech is straightforward: Python, calls to external tools, and an LLM (local or cloud) providing the reasoning layer.
- Ease of Deployment: Easy. Nebula provides a Docker setup (the GitHub repo includes a Dockerfile, and an install script). It’s targeted at Kali/Linux environments – you can install it with pip or run via Docker. The requirements include having those pentest tools installed (which Docker handles automatically). Using Nebula involves running a CLI program in your terminal; it then behaves somewhat like a chatbot within the terminal. Because it’s CLI-focused, there’s minimal GUI overhead – you integrate it into your normal pentest terminal workflow. Nebula’s documentation (on GitHub and the BerylliumSec blog) gives step-by-step installation instructions. For instance, to use OpenAI models you set an
OpenAI_API_KEYenv var [github.com]; for local models, you provide model names/paths. In summary, deploying Nebula is comparable to setting up a typical pentest tool – not much more complex than installing Metasploit. - Self-Hosted LLM Support: Yes. Nebula supports multiple model sources. By design, it can work with OpenAI’s models or self-hosted models; the user can choose which in the engagement settings [github.com]. Specifically, Nebula mentions support for OpenAI API, and also names Meta’s Llama 8B and Mistral 7B models as usable through its CLI [github.com]. This implies Nebula either integrates with local model runtimes (possibly via Ollama or llama.cpp in the backend) or expects the user to run those models and expose them via an API. In any case, you are not forced to use a cloud API – you can configure Nebula to use an open model and run completely offline. This is great for privacy and cost reasons. The trade-off is that smaller local models may be less capable than GPT-4, but Nebula gives you the choice.
- Use Case & Capabilities: Nebula’s focus is to streamline the pentesting process by combining AI with classic tools [medevel.com]. Capabilities include: automated reconnaissance (network scanning, port scanning via Nmap), vulnerability scanning (web scanning via OWASP ZAP, templated scans via Nuclei), and even exploit suggestion or generation [medevel.com]. It performs AI-driven vulnerability analysis on the data gathered – for example, after scanning, the AI can analyze results to highlight likely vulnerabilities or suggest next steps. Nebula can also do automated exploit generation/customization for certain findings [medevel.com], though details are sparse (likely it can suggest exploit code or pick Metasploit modules). A standout feature is intelligent report generation and note-taking: Nebula’s note assistant can summarize tool outputs and link them to CWEs/NIST controls [berylliumsec.com], helping with documentation. Essentially, Nebula covers the whole pentest lifecycle: recon -> scanning -> exploitation -> noting findings. It integrates with popular frameworks, meaning it doesn’t reinvent scanning or exploitation – it uses the best-of-breed tools and adds AI brains on top. This makes its scope broad across network and web app testing. One limitation: out of the box it might be tailored to certain types of engagements (e.g. internal network testing). But the design seems flexible enough to adapt to various targets.
- Agent Reasoning & Contextual Awareness: Nebula uses a single-agent (the “terminal assistant”) that keeps context within an engagement. As you interact through the CLI, it maintains a conversation (invisible to you, it’s the prompt history) that includes previous commands, outputs, and AI analyses. This gives it contextual awareness of what has been done so far. In Nebula Pro, there is mention of an Autonomous Mode where the agent will autonomously chain actions, consulting the user at critical junctures [berylliumsec.com]. This indicates Nebula’s agent does have a reasoning loop: analyze results, decide next action, and either execute or ask permission. The open-source Nebula likely has a simpler loop (since some autonomous features might be Pro-only), but fundamentally the AI in Nebula will analyze tool output and provide suggestions on what to do next [berylliumsec.com, berylliumsec.com]. The Suggestion Assistant reads outputs and offers timely tips (e.g. “The Nmap scan shows port 445 open; perhaps run a SMB vulnerability check”) [berylliumsec.com]. This shows decent contextual awareness of the engagement’s state. Compared to CAI, Nebula is not multi-agent – it’s one AI entity – but within that scope it appears quite context-aware and able to maintain state throughout an engagement (especially since it organizes outputs and can recall them).
- Extensibility & Interoperability: Good, within its design. Nebula integrates several key tools by default [medevel.com]. It likely allows adding new modules or commands – the open source repo might accept contributions of new tool integrations. For example, if you wanted Nebula to use a different web scanner, you could script that and incorporate it. The architecture isn’t plugin-based in a user-friendly way (not like dropping in a file to add a tool), but because it’s open Python code, a developer can extend it. Interoperability: Nebula works alongside your normal tools – you can still run your own commands in the terminal, and Nebula will note them. It stores outputs in organized folders [berylliumsec.com], meaning you can easily access or share those with other systems (like reporting tools). Nebula doesn’t have an API to integrate with other software (it’s more of an interactive assistant), but it outputs standard files and logs that could be consumed by other processes. For a business, Nebula could be integrated into workflows by running it in a tmux session during tests or piping its outputs to ticketing systems, etc., albeit with some custom scripting. BerylliumSec’s focus seems to be making Nebula a part of the pentester’s toolkit, not a platform to extend for others – so extensibility is mostly via code modification. Still, the existing integration of multiple tools and the open model support indicate a flexible design.
- Safety Controls & Ethical Boundaries: Nebula (and Nebula Pro) emphasize user control. In Autonomous Mode, the AI still “consults you at every critical decision point” to avoid going off the rails [berylliumsec.com]. This is a form of safety control – the agent doesn’t, for example, launch a destructive exploit without asking. By default, Nebula likely runs in a guided mode where it suggests and you confirm. Ethical use is addressed in documentation as with any pentest tool: only target systems you have permission to test. Nebula’s open repo presumably has disclaimers. Since it can run potentially dangerous commands (via integrated tools or custom exploit code), it inherits the ethical boundaries of those tools; Nebula itself isn’t known to have additional censorship on its AI output (aside from whatever model is used – e.g. OpenAI’s model might refuse to give certain exploit details, whereas a local model might not). The BerylliumSec site and docs frame Nebula as an assistant to human experts, not a replacement [medevel.com], which implies the human is expected to apply judgment. There’s no mention of explicit safety filters, so the responsibility lies on the tester to approve actions. On a positive note, by automating note-taking and mapping to standards, Nebula encourages ethical reporting and remediation focus (not just exploitation for its own sake) [berylliumsec.com]. Security-wise, Nebula runs locally and uses your API keys – ensure those keys are kept secure (in
.envor config). The tool itself doesn’t enforce a hard boundary on actions, so use it prudently. - Community & Contributor Base: Nebula has a decent community for a niche tool. With ~600+ stars and several forks, it’s seen interest from practitioners. Being backed by a company, much of the development is by the BerylliumSec team, but they engage with the community via GitHub issues and their blog (they published comparisons and invites for contribution). The community is smaller than PentestGPT’s just due to less hype, but arguably more practically oriented (pentesters who want to enhance their workflow). BerylliumSec’s blog posts (e.g. “Nebula in Focus and how it stacks with others” [berylliumsec.com]) show a form of outreach. Contributor-wise, it’s likely that a handful of core developers (from the company) do the majority of commits, with occasional external contributions. The GitHub shows ~490 commits [github.com] which suggests sustained development. As a business considering incorporation, you’d mainly rely on the vendor (BerylliumSec) for continued support, which is actually a plus – there’s an accountable party behind it, and if you need something you could opt for Nebula Pro or request features.
- Documentation & Usability: Nebula’s documentation is split between the open-source README and the vendor’s site/docs. The README gives an overview and likely basic usage instructions (we saw references to config for OpenAI keys, etc.). BerylliumSec’s site provides feature guides and screenshots for Nebula Pro which largely apply conceptually to Nebula OSS [berylliumsec.com, berylliumsec.com]. Usability: Nebula runs as an interactive terminal program. According to BerylliumSec, it’s the industry’s first tool to allow direct AI interaction straight from CLI [berylliumsec.com]. This means if you’re comfortable in terminal, Nebula feels natural – you type questions or commands, the AI responds or executes behind the scenes. It even allows running shell commands from any panel in the interfacebe [rylliumsec.com]. Nebula organizes outputs in folders, making it easy to keep track of findings [berylliumsec.com]. The note-taking agent auto-summarizes and formats notes, simplifying the dreaded documentation phase [berylliumsec.com]. All these usability features make Nebula quite appealing to professionals. The learning curve is low if you know basic pentesting; Nebula’s AI will guide you through the rest. One potential downside: pure CLI may be intimidating for some, but likely users of this tool are already CLI-savvy. Overall, very usable and well-documented through examples.
- Observability & Logging: Nebula keeps an audit trail of your pentest workflow. In Nebula Pro, all command outputs can be logged and a history of commands is maintained [berylliumsec.com]. The open version presumably logs at least the basics (commands run, maybe stores conversation context in a file). It definitely saves outputs of tools it runs (since it has folders for command outputs and screenshots) [berylliumsec.com]. This means you can always go back and see what Nmap found or what exploit code was tried. The suggestion and note agents produce written summaries that are part of the record. While Nebula doesn’t explicitly mention using something like OpenTelemetry (as CAI does), it still emphasizes traceability – “a complete audit trail of your workflow” [berylliumsec.com]. For business use, this is valuable for compliance and review. Also, Nebula likely logs the AI’s suggestions and your confirmations as part of the engagement notes. Because it’s open source, you can modify logging to be more verbose if needed. In short, Nebula provides good observability of the pentest process, largely through persistent output files and command history.
- Security Posture of the Tool: Nebula itself is not known to have security issues; it’s a local CLI tool. However, since it executes real pentest utilities (Nmap, etc.) and possibly exploit code, one should treat the environment with normal caution: run it in a VM or isolated network when testing, to avoid any stray impact on your host. The AI recommendations in Nebula will only target the systems you specify, and any network scanning/exploitation is done through the standard tools (so trust in those tools’ security is the same as usual – e.g. Metasploit modules could crash a service, Nmap could trigger IDS, etc.). Nebula does require API keys if using cloud models, so ensure those keys are protected. The data Nebula sends to an API (if you choose OpenAI) might include sensitive findings; if that’s a concern, use local models. BerylliumSec likely considered security in development: Nebula’s code runs on your machine with your privileges, so if compromised it could be dangerous – thus, keep it updated. The open nature means you can inspect the code for any potential “phone-home” or such; none have been reported. When integrating Nebula into business, treat it as you would any powerful pentest tool – with proper change control and network isolation. The Terminal Assistant concept implies Nebula might maintain a persistent connection with the model API during a session; ensure that channel is secure (it’s HTTPS for OpenAI API by default). Overall, Nebula’s posture is as secure as the environment you run it in and the models you use.
- Update Cadence & Release Practices: Nebula (OSS) doesn’t have clearly numbered version releases on GitHub (no tags noted), but it has frequent commits (490 commits over its life so far) [github.com]. The developers push updates regularly, likely aligning with improvements that also go into Nebula Pro. The community article from Sept 2024 calls Nebula “actively maintained” [medevel.com]. We can infer an update every few weeks or months with new integrations or fixes. BerylliumSec’s dual-license approach (OSS + Pro) means they might not do formal version drops for OSS aside from continuous integration; however, if something major changes, they’ll announce it via blog or GitHub. As a user, you should monitor the GitHub for commits or issues. There may not be an auto-update mechanism, but Docker users can pull the latest image as needed. Release practices are not fully transparent (no changelog in repo), but given the company backing, one can expect ongoing improvements and perhaps occasional “release notes” in their blog. The fact that Nebula integrates multiple external tools means updates might also involve keeping those tool integrations current (for example, new versions of Nuclei templates). So far, the cadence seems steady and responsive to user feedback.
- Scalability & Multi-Agent Support: Nebula is primarily a single-agent assistant geared towards one engagement at a time. However, Nebula Pro highlights “multitasking made easy – launch multiple instances and multiple terminals within each” [berylliumsec.com]. This suggests that even the free Nebula could be run in multiple terminals if you wanted concurrent engagements (each one would be separate, not shared memory). There isn’t a concept of multiple AI agents collaborating in Nebula (that’s more CAI’s domain), but you can certainly have Nebula focus on multiple targets sequentially or via separate sessions. Scalability in terms of target scope: Nebula can handle large target lists by leveraging automation (Nmap scanning a whole subnet, etc., which it can do). It’s as scalable as the underlying tools (which can be scripted for many hosts). For multi-user support, since it’s a CLI, multiple pentesters can each run their own Nebula instance. There’s no centralized server or coordination (unless one uses DAP, BerylliumSec’s other project, for collaboration). In summary, Nebula scales vertically (one agent automating tasks quickly for one test at a time), but not really horizontally (no distributed AI agents working in tandem, no central management of multiple tests). That said, nothing stops creative use – e.g., integrate Nebula with tmux or scripts to handle parallel tasks. If your biz process requires running many automated tests, you might run many Nebula instances in parallel – but each will need its own resources and LLM instance.
HackingBuddyGPT (IPA-Lab) – LLM Assistant for Ethical Hackers
HackingBuddyGPT is an open-source AI assistant developed by a research lab (IPA Lab) to help cybersecurity professionals in a conversational manner [medevel.com]. It’s like a “buddy” that guides you through hacking tasks, tool selection, exploit development, and learning, all via natural language chat.
- Testing notes: We didn’t fully test HackingBuddyGPT, as there were strong indications that integrating it with a local LLM wouldn't be straightforward. However, we’ll be keeping a close eye on its development.
- Project Maturity: Moderate. HackingBuddyGPT emerged around mid-2023. It has ~650 stars and 100+ forks on GitHub [github.com], indicating significant interest, especially in academic and hobbyist circles. With over 600 commits [github.com], it’s actively developed – likely by the IPA Lab team and possibly community contributors. It’s not a corporate product but a lab project; however, the consistent updates and a dedicated website (hackingbuddy.ai) show a commitment to maintaining it. It may not have formal versioned releases, but it is beyond a prototype – one can use it today for practical tasks. It strikes a balance between being a research project and a usable tool, so maturity is medium: not as battle-tested as Nebula, but more evolved than one-off scripts.
- Tech Stack: HackingBuddyGPT is built in Python. It focuses on simplicity – “LLMs in 50 lines of code or less” as the tagline suggests. Internally, it uses the LangChain or similar frameworks to manage conversations and tool usage, though the exact stack is not explicitly stated in the snippet. It can interface with both OpenAI models and local LLMs (if they are presented in an OpenAI-compatible API format) [github.com]. For example, the documentation references using an OpenAI API key or pointing to a locally running model proxy [github.com, github.com]. HackingBuddyGPT also uses a SQLite database to log each session’s trace data [github.com], which is a lightweight way to handle observability. It can connect via SSH to targets (likely using Python’s paramiko or subprocess for command execution) [github.com]. The codebase includes a CLI interface and possibly a web or GUI interface (unclear, but likely CLI since usage examples are with command-line arguments).
- Ease of Deployment: Moderate/Easy. There is a Docker setup mentioned (for Mac, using something like “Gemini-OpenAI-Proxy”) [github.com], which implies you can run a local container to host an LLM and the Buddy. Otherwise, installing is as simple as cloning the repo and installing requirements (which would include OpenAI’s library and any needed paramiko/SSH libs). Running HackingBuddyGPT typically involves preparing a
.envfile with your OpenAI API key and target info [github.com], then executing a Python script or CLI with appropriate flags (for model, target, etc.) [github.com]. The existence of command-line arguments for model selection, context size, host, credentials, etc., shows it’s designed to be launched easily for a given scenario [github.com]. If you have a vulnerable VM accessible via SSH, you provide its IP/user/pass to the tool, and it will attempt a guided exploitation. Deployment complexity is higher than a pure chat interface because you might need to set up that target environment, but the tool itself is straightforward. The documentation (README) provides examples and even a Mac-specific guide (MAC.md) for those on macOS [github.com]. So overall, if you have Python and maybe Docker for local LLM, setup is quite manageable. - Self-Hosted LLM Support: Partial Yes. HackingBuddyGPT was built to use OpenAI’s GPT models primarily, but it explicitly mentions it can also work with “locally run LLMs” for testing [github.com]. In practice, this means if you set up an API endpoint that mimics OpenAI’s (for instance, running a local LLM with an OpenAI-compatible API like the Gemini proxy mentioned [github.com]), the Buddy can use that. The README references how to point
--llm.api_urlto a custom endpoint [github.com]. This is a bit technical but absolutely allows self-hosting: e.g., you could run Llama 2 13B on a local server and have HackingBuddyGPT use it instead of hitting OpenAI. Keep in mind, performance and quality will depend on the model – the project’s name suggests they envisioned GPT-4 usage for best results. But it’s good to see the design supports switching to local models. They caution about OpenAI token costs [github.com], further implying openness to alternatives. So yes, you can integrate self-hosted LLMs, though it might require running an extra component to translate API calls. - Use Case & Capabilities: HackingBuddyGPT acts like a mentor or guide through penetration testing tasks [medevel.com]. Key capabilities include: answering security questions in a conversational way, suggesting what tools to use for a given situation, explaining complex concepts, generating or analyzing exploit code, and providing step-by-step instructions. It’s adaptable to different skill levels – useful for beginners learning and for experts as a second opinion [medevel.com]. It can help with tool selection (“Should I run nmap or gobuster next?”), exploit development (possibly helping craft payloads or modify exploit scripts), and vulnerability analysis. Another big feature is integration with existing tools/workflows [medevel.com] – the agent can interface with tools: indeed, it has the ability to SSH into a target machine and run commands autonomously [github.com]. That means if you point it at a target, it might do things like run
uname -a,whoami, or run exploit scripts on that target, guided by the AI. It also supports report writing assistance [medevel.com] – likely helping to document findings or even draft a basic report of what was done. It emphasizes educational and ethical use, meaning it’s geared to teach and not just break things [medevel.com]. The scope is broad (web, network, etc.), but being a “buddy,” it might not fully automate entire chains; rather, it interacts with you. That said, the autonomous SSH command execution shows it can take initiative (potentially even achieve reverse shells or escalate privileges if the AI figures out how). So its capabilities span from knowledge Q&A up to actual exploitation actions, making it a versatile assistant. - Agent Reasoning & Context: HackingBuddyGPT leverages an LLM conversationally, so it holds a dialog history as context. It is quite context-aware within a given session – it remembers what the user asked and what the agent already did or suggested. It’s designed as a long-form assistant that can handle complex multi-step scenarios, thanks to LLM’s memory (context window can be large, configurable up to 100k tokens in some setups) [github.com]. The agent reasoning is visible to the user as it explains its thought process. It likely uses prompt engineering to have the LLM think step-by-step and maybe uses tools via a REPL (Read-Eval-Print Loop) style approach common in LangChain. The project implements a round limit to avoid infinite loops [github.com], meaning it has a safety cut-off after X interactions if it hasn’t achieved a goal (like root access) – this suggests the agent can pursue a goal (e.g., escalate privileges) through multiple steps, keeping track all along. Additionally, by logging traces to SQLite, the developers can refine the agent’s reasoning over time by reviewing those logs. In use, HackingBuddyGPT feels like chatting with a knowledgeable hacker friend: it asks clarifying questions, keeps track of what information you’ve provided (like “We found ports 80 and 22 open earlier...”), and adjusts its advice accordingly. The contextual awareness is strong but naturally limited to one target environment at a time. It doesn’t have multi-agent yet; it’s one agent juggling tasks (though behind the scenes, that agent can use different “skills” like tool use or direct Q&A). Given it’s built to adapt to user skill, it might even gauge from context how much detail to provide. Overall, the reasoning quality depends on the LLM used but is generally high with GPT-4, and context handling is explicitly a feature (with large context windows supported) [github.com].
- Extensibility & Interoperability: HackingBuddyGPT is somewhat extensible. It was made to be “50 lines of code” minimal for core logic, implying simplicity. If one wants to add new tools or capabilities, they might modify the code to add a new command the agent can run. For example, currently it can connect over SSH; if you wanted it to interact with Metasploit, you could integrate that by adding a function call in the agent’s toolset. The project likely uses an agent framework where tools are defined as functions the LLM can invoke. As a lab project, the maintainers might welcome contributions for new integrations. In terms of interoperability, since it’s open source, you could call HackingBuddyGPT from other scripts (imagine using it as a library to get recommendations or to automate a task). However, it doesn’t expose a clean API or plugin system out-of-the-box – it’s intended to be run as a stand-alone helper. It does integrate with existing pentest workflows by design [medevel.com]: meaning you can use it alongside your manual testing, and it will play nice (not taking over exclusive control). For instance, you can run your own Nmap and paste the output to the Buddy and it will analyze it. Or let the Buddy run Nmap for you via SSH. That kind of interoperability (between human and AI workflows) is the core selling point. It also builds a community-driven knowledge base – presumably the more it’s used, the more prompts/insights get refined [medevel.com], although there’s no central server for knowledge, just the community sharing prompt ideas. In summary, adding new features might require moderate coding, but the existing feature set is broad enough for common tasks. It’s not as modular as CAI, but it’s flexible in being able to work with whatever tools/commands you direct it to.
- Safety Controls & Ethical Boundaries: The authors explicitly stress educational and ethical use [medevel.com]. The assistant likely refuses to assist in clearly illegal activity outside an ethical hacking context (although with local models that filter is up to the model’s training). By focusing on “helping ethical hackers,” it frames all advice as if for authorized pentests. One built-in safety is the round limit – preventing the AI from going on forever or getting stuck, which can also act as a brake if it’s not succeeding [github.com]. Another safety measure is requiring an SSH login to do autonomous actions: it doesn’t just attack random hosts; you must provide credentials or at least an IP, implying you have some access. It also likely doesn’t execute tools on its own machine without user confirmation. The user has to pass
--conn.hostand credentials, which is an explicit opt-in to “go live” on that target [github.com]. If you don’t provide that, it might operate in a recommend-only mode. HackingBuddyGPT’s documentation also warns about costs (to ensure users are aware and don’t overspend) [github.com], which is a minor safety for your wallet. Regarding content safety: using OpenAI’s API means the model might refuse certain instructions (like creating malware) unless framed in a valid security testing context. With local models, no such filter exists, so ethical use truly depends on the user’s integrity. The project likely provides disclaimers that it’s for authorized testing only. We haven’t seen evidence of a specific “ethical guardrail” algorithm in the code (like checking target scope, etc.). It really functions as a smart assistant that trusts the user to be ethical. As such, the safety controls are mostly advisory and in user hands, not enforced by the tool beyond practical limits like round count and needing explicit target details. - Community & Contributor Base: HackingBuddyGPT has an academic/research community vibe. IPA Lab (presumably a university or institute research group) developed it, and they have made it open for the community. The star count ~657 and forks ~103 show a good number of people have tried it [github.com]. Its community likely includes security enthusiasts and students who use it for learning. There are ~10 issues and some PR activity on GitHub [github.com], indicating users are engaging (reporting bugs, suggesting features). The core maintainers are probably the lab members. There’s also a mention of a community-driven knowledge base [medevel.com], which could mean they encourage users to contribute back exploit patterns or prompts that worked well, perhaps via the GitHub discussions or wiki. The fact it’s open source and free fosters a helpful community – one can find blog posts or Reddit threads discussing it (for example, comparing PentestGPT and HackingBuddyGPT). For a business, the support comes from this open community and the lab’s continued interest. Since it’s not a commercial product, support might not be guaranteed long-term, but as long as IPA Lab finds it useful for research/education, they will maintain it. The tool sits in a niche where community contributions (like adding a new CTF solution as an example) are quite possible. So the community size is moderate, but active in spirit.
- Documentation & Usability: The README on GitHub is detailed. It covers setup, and likely includes usage examples for different scenarios (they even have separate docs like MAC.md for Mac specifics, hinting at thorough docs)github.com. They outline how to set environment variables, run the script with various options, and what to expect. The key features are listed clearly in the project description [medevel.com, medevel.com]. Usability is high if you follow the docs – it’s meant to be up and running quickly (the “50 lines of code” mantra suggests they want it simple to use, not a complex configuration). In practice, using it involves launching it with some flags or entering a chat loop. Once running, it provides a conversational interface [medevel.com]. This is user-friendly: you ask in plain English, it replies in kind. For example, you might say “I have a low-privilege shell on a Linux box, what can I try next?” and it would respond with suggestions. It tailors advice to skill level (the agent won’t overwhelm a newbie with jargon, presumably) [medevel.com]. The integration with tools is smooth: if it needs to run a command, it will either instruct you or execute it if configured to do so. The outputs from tools are then explained back to you. That kind of interactive pedagogy makes it quite approachable even for less experienced users. It’s like having StackExchange plus an exploit tutor in one. The only usability caveat: it’s still a command-line app; those not comfortable with terminals might struggle initially. But compared to writing all commands manually, HackingBuddyGPT likely reduces effort and improves understanding, which is a huge usability win in the pentest process.
- Observability & Logging: By design, HackingBuddyGPT logs every interaction to a local SQLite database [github.com]. This means each question, answer, and action is recorded persistently. That’s great for reviewing what steps were taken during a pentest. The log can also be used for debugging the AI’s behavior or for audit purposes. Additionally, the tool outputs to console all the major actions (and any tool outputs when run). If it executes commands via SSH, you will see those commands and their results in the console in real-time, which you can copy or save. The logging to DB is automatic, so even if you forget to save console output, you can later extract the conversation and events from the database. This emphasizes transparency – you can see exactly what the AI did or recommended. Observability also extends to parameters like context window or model usage: since you specify them, you know the limits of what it “remembers” [github.com]. The project likely allows adjusting verbosity or debug output if needed (for example, to see the raw prompts being sent). All in all, HackingBuddyGPT provides a good logging mechanism out-of-the-box, which is very useful for learning and accountability. From an organizational standpoint, you could require saving the SQLite logs as part of test evidence. One should ensure sensitive data in those logs is protected, as it will contain potentially exploit payloads, passwords (if given), etc. But that’s a manageable concern.
- Security Posture of the Tool: HackingBuddyGPT, when used with OpenAI, will send data to the API – so similar considerations of data confidentiality apply as with PentestGPT. Using a local model alleviates that. The tool does store logs of potentially sensitive info (including credentials, findings) in a local DB; securing that file is important (e.g., don’t leave it world-readable). The ability of the AI to execute commands on a target via SSH means the tool is effectively acting with the same privileges as the user on that target. If the target is hostile or has monitoring, be aware. The Buddy runs on your machine, so if the target somehow could exploit the Buddy’s process (unlikely, since mostly it’s the Buddy exploiting the target), that would be a risk. Essentially, treat the environment as you would when manually doing the same actions. The code is open – so far no known malicious aspects. A subtle point: if using a powerful LLM, the Buddy might craft some aggressive exploits; ensure those don’t violate your test rules. The Buddy itself will not hold back unless the model filters it. Also, since it can run commands, one must be cautious that an LLM glitch doesn’t run something harmful on the wrong system. But because you explicitly give it the target connection and presumably start the session when you’re ready, it should confine activity to intended hosts. The Gemini-Proxy suggestion indicates they care about security – e.g., on Mac using Docker to run local models to avoid dependency nightmares. Summarily, HackingBuddyGPT’s security depends on safe configuration (API keys, target credentials) and the user watching its actions (though it can run autonomously, you should still supervise). Given it’s often used in learning contexts, it likely errs on the side of caution (explaining rather than immediately firing exploits, unless told to). There have been no reports of the tool causing unintended damage by itself – it does what an ethical tester would do, but with AI guidance.
- Update Cadence & Release Practices: The project is under active dev, but being a lab project, the release cycle might align with academic semesters or the lab’s focus. The last commit timeframe (we see 641 commits total [github.com], which is quite high) suggests frequent iterative improvements. No explicit version numbers are advertised – it’s more of a continuous update model. The commit history shows they are likely refining features like the SSH functionality, model integration, etc. Every now and then, they may write a Medium article or conference paper and update the repo accordingly. For a business user, it means new features might drop unexpectedly; you’d watch the repo or pin to a particular commit that’s stable for you. There haven’t been formal releases (no pip package, no tagged releases listed in the snippet). So update by pulling the latest from Git. The “50 lines” approach also suggests the core is small and changes can be managed easily. We can consider the update cadence moderately frequent (as of 2024, likely every few weeks to fix issues or add minor features). If IPA Lab continues research in AI for hacking, expect updates to continue. Release practices are informal – no changelog, but commit messages and the README will reflect new capabilities. Testing of updates might not be as rigorous as a company product, so one should verify new changes in a safe environment.
- Scalability & Multi-Agent Support: HackingBuddyGPT runs one agent (buddy) per session. It’s not meant for parallel multi-agent scenarios. You can run multiple instances on different terminals if you want to handle multiple targets at once, but they won’t share knowledge. The agent itself is designed for one target engagement at a time. It can perform multiple steps sequentially (like a playbook) on that target thanks to its loop and SSH exec feature, but that’s still a single-threaded workflow. Scalability in terms of target coverage: if you have many hosts, the Buddy would treat each separately (you’d likely focus it on one host or one subnet at a time). There’s no orchestrator to manage many buddies concurrently. This tool shines in depth (going deep on a target) rather than breadth (covering a wide range at once). For multi-agent (collaborative agents) – not present here; it’s one LLM agent. For multi-user, each user can run their own instance easily. So, in a team, multiple team members could each use a Buddy on their part of the assessment. It doesn’t yet have a notion of sharing state among them (though conceivably one could share the SQLite log to another to continue where you left off, but that would be manual). Summing up, HackingBuddyGPT is not built for large scale automation, but as a scalable assistant per user. If needed, you can spin up multiple sessions for multiple tasks, but oversight becomes harder then. It’s best at interactive use-case, not brute-force scanning of thousands of IPs (for that, you’d pair it with traditional scanners and maybe feed results in one by one).
Other Noteworthy Projects and Research
(Beyond the top projects above, there are several other open-source initiatives exploring AI-driven pentesting. They vary in maturity and approach, from older machine learning tools to cutting-edge experiments. We list a few for completeness.)
- GyoiThon – Machine Learning Pentest Tool (2018). GyoiThon is an older project that pioneered AI in pentesting by using ML (not LLMs) for web app vulnerability discovery [github.com]. It automates web scanning, identifies running software (CMS, frameworks) on targets, correlates them with known CVEs, and even launches Metasploit exploits automatically [github.com, github.com]. It was introduced at Black Hat Asia Arsenal 2018 and DEF CON 26 [github.com], demonstrating next-gen automation at the time. Maturity: It’s relatively mature in that it’s a finished tool (version 0.0.4 as of 2019, presented at multiple industry conferences) [github.com]. However, it may not be actively updated now. Tech: Python-based, with some ML for banner analysis and a rules engine; integrates with Metasploit RPC. Deployment: Runs on Kali/Linux, with configuration files for targets. Self-hosted ML: Yes (it’s offline, uses local ML models). Use Case: Web server intel gathering and exploitation – it crawls targets, uses Google and Censys for info, then picks exploits [github.com]. Agent Reasoning: Minimal compared to LLMs – it’s more of a scripted automation with ML classification (no “conversation” or adaptive planning beyond its coded logic). Extensibility: Low (not designed for user-extended logic, though one could update its signatures). Safety: Focuses on non-destructive testing by default, with an option to launch exploits if authorizedgithub.com. Community: 700+ starsgithub.com, used in research and by some professionals historically. Observability: It produces detailed reports of findings and actions taken. Security: As with any exploit tool – ensure legal use. Note: GyoiThon demonstrated the feasibility of automated pentesting and influenced later LLM-based approaches, but it doesn’t have the interactive intelligence of an LLM agent. It’s still usable for automating recon and known exploit checks, and can be incorporated as a module in an AI agent pipeline (for example, an LLM agent could call GyoiThon for initial recon data).
- DeepExploit & AutoPentest-DRL – Deep Reinforcement Learning for Pentesting. These projects (DeepExploit by Isao Takaesu, 2018 [github.com], and AutoPentest-DRL by JAIST researchers, 2020s [medevel.com]) use reinforcement learning (RL) to autonomously navigate attack paths. DeepExploit was a fully automated framework that linked with Metasploit to train an agent to efficiently exploit target systems [github.com]. It used an A3C deep RL model with multi-agent distributed learning to teach itself exploitation strategies [github.com]. Key features included: self-learning exploits (no prior exploit dataset needed) [github.com], pivoting after initial compromise for deep penetration into internal networks [github.com], and covering the whole kill chain (intelligence gathering, vulnerability analysis, exploitation, post-exploitation, reporting) without human intervention [github.com]. AutoPentest-DRL similarly applies Deep Q-Networks to automate network pentesting, exploring and exploiting vulnerabilities in a simulated environment [medevel.com]. Maturity: These are research prototypes (DeepExploit was labeled beta, and AutoPentest-DRL is an academic project). They are not plug-and-play enterprise tools. Tech: Python with TensorFlow/Keras for the RL model, integrated with Metasploit and environment simulation. Deployment: Complex – require setting up training environments, GPU acceleration (for RL training) [github.com, github.com]. Not something you casually run on prod networks. Self-hosted: Yes, entirely local. Use Case: Demonstrating that an AI agent can learn to hack multiple targets efficiently. In practice, could be used to automatically test a range of IPs and have the agent find a path to a goal (like domain admin), given enough training. Agent Reasoning: Based on reward feedback – e.g., reward for successful exploit, thus it learns optimal exploit sequences [github.com]. It’s not human-readable reasoning, but it’s effective within the training scope. Extensibility: Low for DeepExploit (you’d have to retrain the model to add new exploits). Safety: These were confined to lab settings (they come with strong warnings to only run on controlled environments [github.com]). If loosed on a real network, they might cause unpredictable impact because they try many exploits. Community: Niche – known in academic circles, not widely used by practitioners due to complexity. Observability: They output logs of actions and learned policies, but the decision-making is a black box (neural network). Security of tool: They run Metasploit and potentially destructive payloads, so caution is needed. Note: While not directly practical for a business process today, they represent the frontier of autonomous hacking AI. Some concepts (like training an agent for specific environments) might be incorporated into future products. If your business is research-oriented, experimenting with these could provide insight. Otherwise, they are interesting case studies rather than ready-to-use tools.
- PentestAI (Auto-Pentest-GPT-AI by Armur Labs) – Autonomous Agent with Fine-Tuned Local LLM. PentestAI (sometimes called “HackRecon” in the repo) is a newer project (circa 2023) that uses a locally fine-tuned LLM to conduct penetration tests in an automated fashion [github.com]. Armur Labs fine-tuned the OpenHermes 7B model on penetration testing command sequences, essentially “jailbreaking” it to output actionable commands and finetuning for Kali Linux tools [github.com]. The result is an AI that can provide guided, actionable steps and even automate command execution for deep pentests [github.com, github.com]. Maturity: Early-stage/Poc – ~145 stars, a few contributors [github.com, github.com]. It’s experimental but functional. Tech: Python, uses HuggingFace Transformers to load the 7B model (OpenHermes Mistral) locally [github.com]. Requires a decent GPU for the model. Integrates with Kali Linux: checks and installs missing tools, then uses Python
os.popenor subprocess to run them [github.com, github.com]. Deployment: You need to download the model (provided via HuggingFace) and point the script to it [github.com]. Install a few Python libraries (transformers, torch) and ensure you have a Kali or similar environment (the script auto-installs tools like nmap, nikto, etc., if missing) [github.com]. Runningpentest_ai.pylaunches an interactive prompt where the AI asks for environment info (OS selection: Kali/Windows/Mac, etc.) [github.com], then proceeds. Self-hosted LLM: Yes – it runs entirely offline with the 7B model (no OpenAI API needed after model is downloaded). Use Case: Automated reconnaissance and exploitation on a single target. For example, it might ask for target IP, then run Nmap, then based on open ports run specific tools (it parses its own outputs to decide next steps) [github.com]. It’s like AutoGPT but specifically trained for pentest steps, and it actually executes commands. It produces a running commentary and results, which can be used to build a report. Agent Reasoning: Uses chain-of-thought baked into the model (the fine-tuning presumably gave it a format like: think -> decide tool -> output command). It identifies keywords in its own output to trigger tool execution (e.g., if the model’s text mentions “nmap”, the script will run Nmap) [github.com]. This is a clever yet somewhat brittle way to link the LLM and system. The context awareness is limited by the 7B model’s capacity, but since it’s fine-tuned, it’s focused on relevant context (it knows to follow a sequence of enumeration, scanning, exploiting based on feedback). It doesn’t have an external memory, but it reads command output and can adjust accordingly, so it’s context-aware within one run. Extensibility: Medium – it’s more closed than CAI but you could fine-tune a new model or alter the tool list. The code is commented and straightforward to modify (for example, adding a new conditional to handle if model mentions “sqlmap”, you could integrate that). Safety: Being fully offline and user-run, it will attempt any exploit its model was trained on. The fine-tuning likely included guidance for common tasks, but if pointed at a production system it could still cause disruptions. There’s no user confirmation step when it decides to run a tool – it just does it. So ensure targets are non-production or you closely watch and Ctrl+C if needed. Ethically, it’s only as good as its training – hopefully it was trained with an ethical angle, but essentially it will hack the target relentlessly (“until the server breaks down or you stop the tool,” as an Armur LinkedIn post put it). Thus, treat it like an autonomous red team that needs boundaries (network segmentation, etc.). Community: small but growing; Armur’s posts suggest interest. It’s open-source, and a few contributors are listed [github.com]. Documentation & Usability: The README is detailed with setup, code explanations, and a conclusion [github.com, github.com]. They even comment code snippets in README to explain how it works [github.com, github.com] – great for transparency. Running it is interactive but not conversational like a chat – it’s more a guided script (prompts for environment, then automates). So usability is good if you just want it to do its thing, but you don’t chat with it much. Observability: It prints out what it’s doing and why, and you see all command outputs in console, but it might not log them to a file by default. You’d need to capture the stdout for record-keeping. No built-in telemetry beyond print statements. Update Cadence: With ~5 tags/releases on GitHub in a short time [github.com], it seems they are actively improving it (maybe integrating larger models or new techniques). As a business, you’d experiment with this but might not rely on it heavily yet; it’s an exciting glimpse at fully autonomous pentesting with small models. - PentestAI-ML (ThreatDetect-ML by haroonawanofficial) – Machine Learning Pentest Automation. This is a recent open-source project that integrates ML with Metasploit to automate vulnerability detection and exploitation [medevel.com, medevel.com]. It maps identified CVEs to Metasploit payloads and auto-deploys them, learning from responses to improve attack precision [github.com, github.com]. Essentially, it’s trying to be an AI-enhanced Metasploit wrapper. Maturity: Low – only ~69 stars [github.com] and 15 commits [github.com]. Likely a personal project (perhaps in early dev). Tech: Python, uses some ML model trained on exploit success, integrates with Metasploit and scanners. Use Case: Fully automate port scanning, CVE identification, exploitation, and produce a report. It’s aimed at port, web, and application security testing with predictive threat detection [medevel.com, medevel.com]. Unique aspect: The ML tries to anticipate threats, not just react, presumably by generalizing from known exploits to variations. Current state: Experimental – it might work on some known vulnerabilities but not broadly validated. Integration: It directly ties into Metasploit (calls it to exploit CVEs) [medevel.com]. Extensibility: unclear, probably not much without diving into code. Given its low activity, one would be cautious about using it in production. It’s an example of many such small projects aiming to combine CVE data, ML, and auto-exploitation. Over time, these ideas might merge into larger projects or die off if not maintained. For now, PentestAI-ML/ThreatDetect-ML is more a curiosity – if you incorporate something into your process, the above larger projects are more promising. But keeping an eye on these small projects can reveal novel techniques (for instance, using ML classification to prioritize which exploit to try first, which could be useful in a larger agent context).



